Chapter 1 R的基础知识
1.1 科学计算器
四则运算:
(1 + 2 * 4)/3 - 1.3# [1] 1.7指数运算: 例如,100的0.5次方:
100^0.5# [1] 10对数运算:
log(2)# [1] 0.6931472注意这是自然对数,与excel里的表述不一样。若以10为底,需明确标注:
log10(2) # [1] 0.30103类似地,以2为底的对数是:
log2(2)## [1] 1特殊的常数: e是自然对数的底,e=2.718…, exp(1) = e^1;用于指数函数
exp(1)## [1] 2.718282pi = 3.14159…圆周率
sin(pi/2)## [1] 1科学计数法,6.22*10^23,注意这里e不是自然对数的底
6.22e23## [1] 6.22e+23绝对值
abs(-10) ## [1] 101.1.1 取整
round()函数取整原则:四舍六入五成双
round(2.3)## [1] 2round(2.6)## [1] 3round(2.5)## [1] 2round(3.5)## [1] 4floor(2.6) #向下取整## [1] 2ceiling(2.3) #向上取整## [1] 3trunc(2.3)#取整数部分## [1] 2trunc(2.6)## [1] 21.1.2 保留有效数字
原则:四舍六入五成双
round(pi, 2) #保留2位小数## [1] 3.14round(pi, 3) #保留3位小数## [1] 3.142signif(pi,2) #保留2位有效数字## [1] 3.1signif(pi,3) #保留3位有效数字## [1] 3.141.2 变量赋值
在R语言里,用符号”<-”给变量赋值。它的功能和”=”几乎等同。但是用<-是一种传统,我们最好遵守。
x1 = 12
x1## [1] 12x2 <- 23
x2## [1] 23y <- x1 + x2
y## [1] 35x1 + x2 -> z
z## [1] 351.3 变量取名规则
变量名只能是字母、数字、点(
.)、下划线(_)的组合只能以字母或点开头;不能以数字、下划线开头
对字母大小写敏感,
a和A是不同的变量变量名不能含有空格:
x_1,x.1都可以,但x 1不可以;推荐x_1形式的命名,理由是方便阅读,方便记忆
1.4 变量类型
| 变量 | 含义 |
|---|---|
| integer | 整数 |
| numeric | 实数 |
| character | 字符 |
| logical | 逻辑值(TRUE或FALSE) |
class(as.integer(1.2)) #将1.2转化为整数,并查看其类型## [1] "integer"class(pi) # pi = 3.1415......## [1] "numeric"class("Xiamen")## [1] "character"class(c(TRUE,FALSE))## [1] "logical"1.5 常用的数据类型
| 数据类型 | 说明 |
|---|---|
| vector | 向量,元素可以是数值、字符串、逻辑值 |
| factor | 因子,水平,是离散的,以整数vector形式储存,映射到字符串上 |
| matrix | 矩阵,所有元素的类型(numeric, character等)需一致 |
| data frame | 数据表,和matrix类似,但每列的类型可以不一致 |
| list | 清单,与vector类似,但每个元素的类型可以不一致,且可以是任何数据类型(例如numeric,data frame, list…) |
1.6 数据类型强制转化(coercing)
t_1 <- c("1", "2", "3.4") #字符,无法进行计算
t_1## [1] "1" "2" "3.4"class(t_1)## [1] "character"t_2 <- as.numeric(t_1) #转化为数值,就可以计算了
t_2## [1] 1.0 2.0 3.4class(t_2)## [1] "numeric"t_3 <- as.factor(t_2) #数值转化为因子,非常有用的功能,以后详述
t_3## [1] 1 2 3.4
## Levels: 1 2 3.4class(t_3)## [1] "factor"1.7 缺失值(NA)和无穷大(Inf)
实验数据经常会有缺失值,缺失值的处理对于数据分析非常重要。
v0 <- c(1, 3, 4, NA) #第4个数缺失
v0## [1] 1 3 4 NAis.na(v0) #判断是否有缺失值## [1] FALSE FALSE FALSE TRUEv0[is.na(v0)] <- 0 #将缺失值替换为0
v0## [1] 1 3 4 0logv0 <- log(v0) #对数据进行自然对数转化,产生了负无穷大值(-Inf)
logv0## [1] 0.000000 1.098612 1.386294 -Infis.infinite(logv0) # 检查是否有无穷大,包括Inf和-Inf## [1] FALSE FALSE FALSE TRUElogv0[is.infinite(logv0)] <- NA #将无穷大替换为缺失值NA
logv0## [1] 0.000000 1.098612 1.386294 NA1.8 向量(vector)
1.8.1 用函数c( )生成向量
“c”的含义: 1. combine
2. concatenate [kɒn’kætɪneɪt] vt.把 (一系列事件、事情等)联系起来
- 数值向量
v1 <- c(1.4, 3, 10.9, -7)
v1## [1] 1.4 3.0 10.9 -7.0- 字符向量
v2 <- c("apple","organge","banana")
v2## [1] "apple" "organge" "banana"- 逻辑值向量
v3 <- c(TRUE,FALSE,TRUE,FALSE)
v3## [1] TRUE FALSE TRUE FALSE1.8.2 用 seq()生成等差序列
seq(from = 10, to = 100, by = 10) ## [1] 10 20 30 40 50 60 70 80 90 100from是第一个值,to是最后一个值,by是相邻两个数的间隔值。
可以简略成(默认第1个数赋给from,第2个数赋给to,第3个数赋给by) :
seq(10, 100, 10)## [1] 10 20 30 40 50 60 70 80 90 100怎么使用seq()函数?–查看帮助信息。
执行代码?seq, 你会在Help栏看到如下信息:
Usage
seq(…)
Default S3 method:
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)), length.out = NULL, along.with = NULL, …)
耐心读一读,你可以看懂。读懂之后,你还可以这么使用seq():
seq(10, 100, length.out = 19)## [1] 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100length.out是数列的长度
v2 <- seq(10, 100, length.out = 19)
v2[12]## [1] 651.8.3 用:符号生成连续自然数序列
1:10## [1] 1 2 3 4 5 6 7 8 9 10v3 <- 20:30
v3## [1] 20 21 22 23 24 25 26 27 28 29 301.8.4 用rep()重复元素,生成向量
rep(8, 5)## [1] 8 8 8 8 8rep("ha", 6)## [1] "ha" "ha" "ha" "ha" "ha" "ha"rep(1:3, 2)## [1] 1 2 3 1 2 3rep(1:3, each = 3)## [1] 1 1 1 2 2 2 3 3 3rep(1:3, each = 3, times=2)## [1] 1 1 1 2 2 2 3 3 3 1 1 1 2 2 2 3 3 3这个功能在自动填充数据表s时非常有用,例如,填充treatment,replicate编号。
1.8.5 向量信息提取与运算
v1 <- c(1.4, 3, 10.9, -7)
v1[3] # 引用第3个元素## [1] 10.9v1 + 10 # 每个元素均加10## [1] 11.4 13.0 20.9 3.0v1 * 10 # 每个元素均乘以10## [1] 14 30 109 -70v1^2 #每个元素均求平方## [1] 1.96 9.00 118.81 49.001.8.6 针对向量的统计运算
v4 <- seq(60, 100, 5)
v4## [1] 60 65 70 75 80 85 90 95 100summary(v4) ## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 60 70 80 80 90 100mean(v4) #算术平均值## [1] 80median(v4) #中位数## [1] 80sd(v4) # 标准差## [1] 13.69306min(v4) # 最小值## [1] 60max(v4) # 最大值## [1] 100range(v4) #范围:最小值~最大值## [1] 60 1001.9 矩阵(matrix)
1.9.1 用matrix()函数生成一个矩阵
m1 <- matrix(1:18, nrow=3, ncol=6)
m1## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 1 4 7 10 13 16
## [2,] 2 5 8 11 14 17
## [3,] 3 6 9 12 15 18默认按列排元素,可用byrow更改为按行排
m2 <- matrix(1:18, nrow=3, ncol=6, byrow=T)
m2## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 1 2 3 4 5 6
## [2,] 7 8 9 10 11 12
## [3,] 13 14 15 16 17 181.10 数据表(data frame)
1.10.1 用data.frame()函数生成一个数据表
数据表储存以下信息:学生姓名、性别、考试分数
student <- c("Tom", "Jack", "Mingming", "Alice", "Feifei")
sex <- c("Male", "Male", "Male", "Female", "Female")
score <- c(83, 72, 80, 92, 95)
data.frame(student, sex, score)## student sex score
## 1 Tom Male 83
## 2 Jack Male 72
## 3 Mingming Male 80
## 4 Alice Female 92
## 5 Feifei Female 95可将该数据表储存于变量d1中,也可以说给数据表取个名字叫d1
d1 <- data.frame(student, sex, score)1.10.2 引用data.frame中的信息
引用d1数据表的student列有两种方法,一种是用名称,一种是用编号:
d1$student ## [1] "Tom" "Jack" "Mingming" "Alice" "Feifei"d1[ , 1] #逗号前是行号,逗号后是列号## [1] "Tom" "Jack" "Mingming" "Alice" "Feifei"引用d1数据表第2个学生的成绩有两种方法,一种是用名称,一种是用编号:
d1$score[2]## [1] 72d1[2, 3] ## [1] 721.10.3 查看base R自带的数据
data() #用此函数查看R自带的数据,以下是节选。可以用这些数据来测试、交流你的统计、绘图代码。
| 数据名称 | 简介 |
|---|---|
| BOD | Biochemical Oxygen Demand |
| ChickWeight | Weight versus age of chicks on different |
| ToothGrowth | The Effect of Vitamin C on Tooth Growth in Guinea Pigs |
| co2 | Mauna Loa Atmospheric CO2 Concentration |
| iris | Edgar Anderson’s Iris Data |
| mtcars | Motor Trend Car Road Tests |
| npk | Classical N, P, K Factorial Experiment |
| precip | Annual Precipitation in US Cities |
| pressure | Vapor Pressure of Mercury as a Function of Temperature |
| rivers | Lengths of Major North American Rivers |
1.10.4 查看数据表的常用命令
- 查看数据
iris表头(默认前6行,可更改)
head(iris )## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa–
- 查看表尾(默认最后6行,可更改,此处改为4行)
tail(iris, 4)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 147 6.3 2.5 5.0 1.9 virginica
## 148 6.5 3.0 5.2 2.0 virginica
## 149 6.2 3.4 5.4 2.3 virginica
## 150 5.9 3.0 5.1 1.8 virginica- 查看数据表有哪些变量
names(iris) ## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"以上结果显示5个变量的名称,每1列是1个变量。
- 查看数据表的尺寸(dimension),即行数和列数
dim(iris) ## [1] 150 5结果显示150行,5列。
length()显示数据表的列数,即变量数;显示vector的长度,即元素数。
length(iris) #5列## [1] 5length(iris$Species) #150行## [1] 1501.10.5 查看数据表的其他性质
- 查看数据表的结构
str(iris) ## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...前4列均为numeric,最后一列为factor
- 查看数据表的概要
summary(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## 包含了每列的最小值、25%分位数、中位值、均值、75%分位数、最大值
- 查看
iris这个对象(object)的类型
class(iris) ## [1] "data.frame"当然是data.frame类型。
1.10.6 合并数据表
d1## student sex score
## 1 Tom Male 83
## 2 Jack Male 72
## 3 Mingming Male 80
## 4 Alice Female 92
## 5 Feifei Female 95d2 <- data.frame(age = c(20, 19, 20, 21, 19))
d2## age
## 1 20
## 2 19
## 3 20
## 4 21
## 5 19- 合并列(
column binding)
cbind(d1, d2) ## student sex score age
## 1 Tom Male 83 20
## 2 Jack Male 72 19
## 3 Mingming Male 80 20
## 4 Alice Female 92 21
## 5 Feifei Female 95 19- 合并行(
row binding)
rbind(d1, d1)## student sex score
## 1 Tom Male 83
## 2 Jack Male 72
## 3 Mingming Male 80
## 4 Alice Female 92
## 5 Feifei Female 95
## 6 Tom Male 83
## 7 Jack Male 72
## 8 Mingming Male 80
## 9 Alice Female 92
## 10 Feifei Female 951.11 读入数据
四种方法:
| 代码 | 说明 |
|---|---|
d1 <- read.table("clipboard", head = T) |
从剪贴板(ctrl+C)直接读取,适合于小数据表的快速操作 |
d2 <- read.csv(file.choose()) |
弹出对话框,点击鼠标选取文件,读取csv格式的数据 |
d3 <- read.csv("你的文件名.csv") |
从工作目录下直接读取csv格式的数据 |
d4 <- read_excel("你的文件名.xlsx", sheet = 1) |
直接读取xlsx文件中某个sheet(此处为sheet1)中的数据,需先加载readxl程序包 |
1.12 输出数据
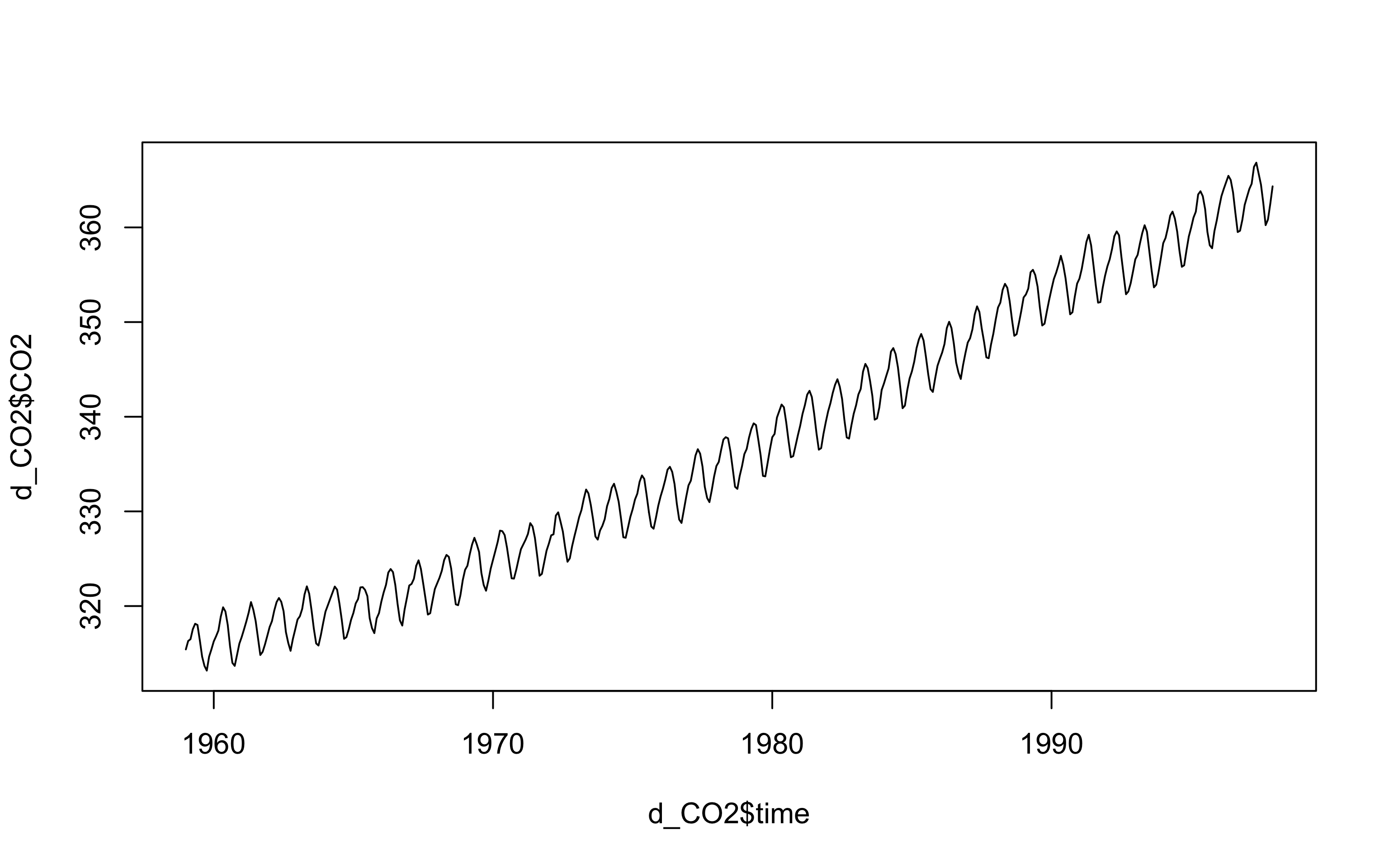
co2是R自带的时间序列数据,此处将其转化为data.frame,用write.csv()函数将数据储存于名为“CO2_data.csv”的文件中。你可在工作文件夹下找到该文件。
d_CO2 <- data.frame(time = time(co2), CO2 = co2)
write.csv(d_CO2, "CO2_data.csv")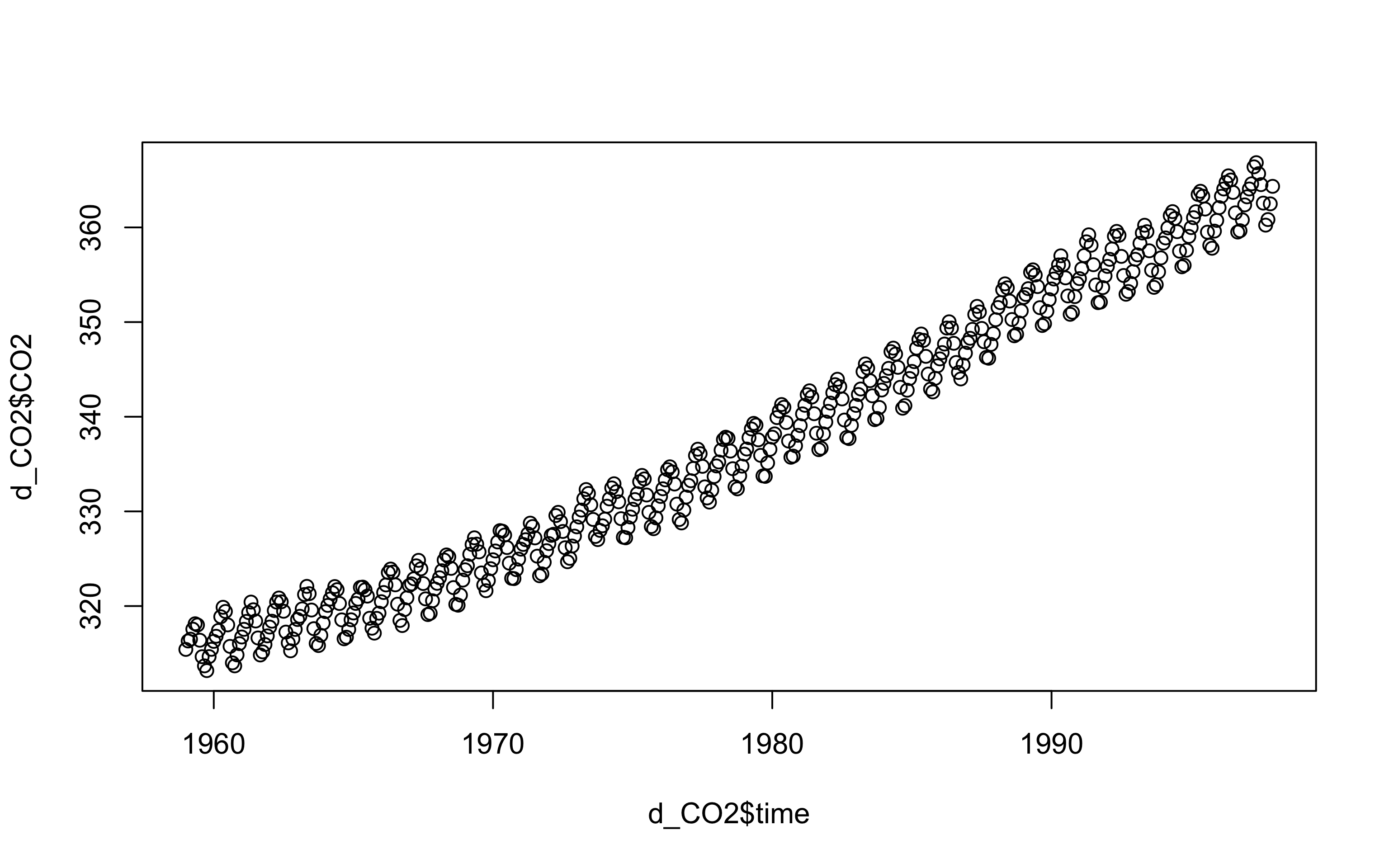
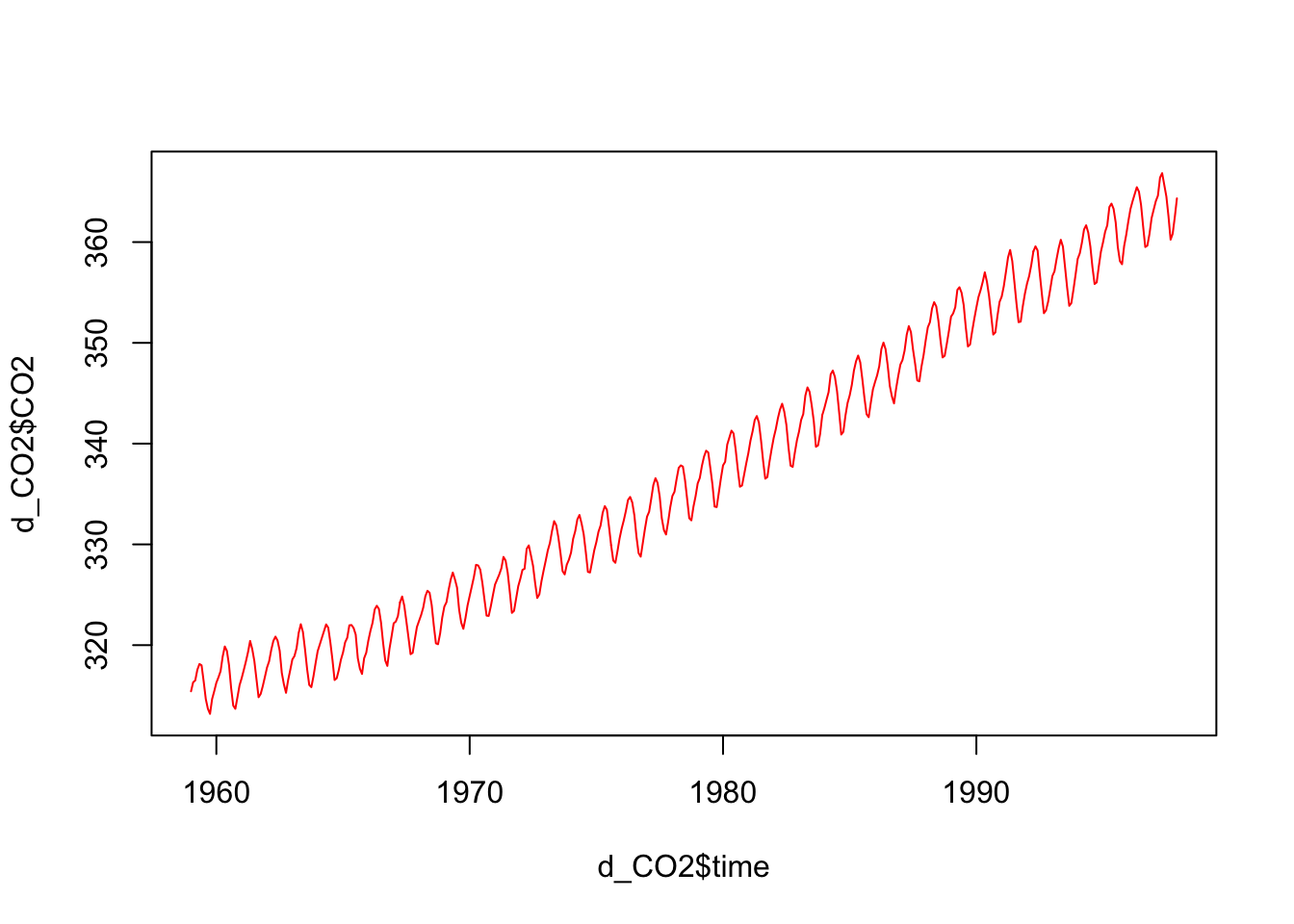
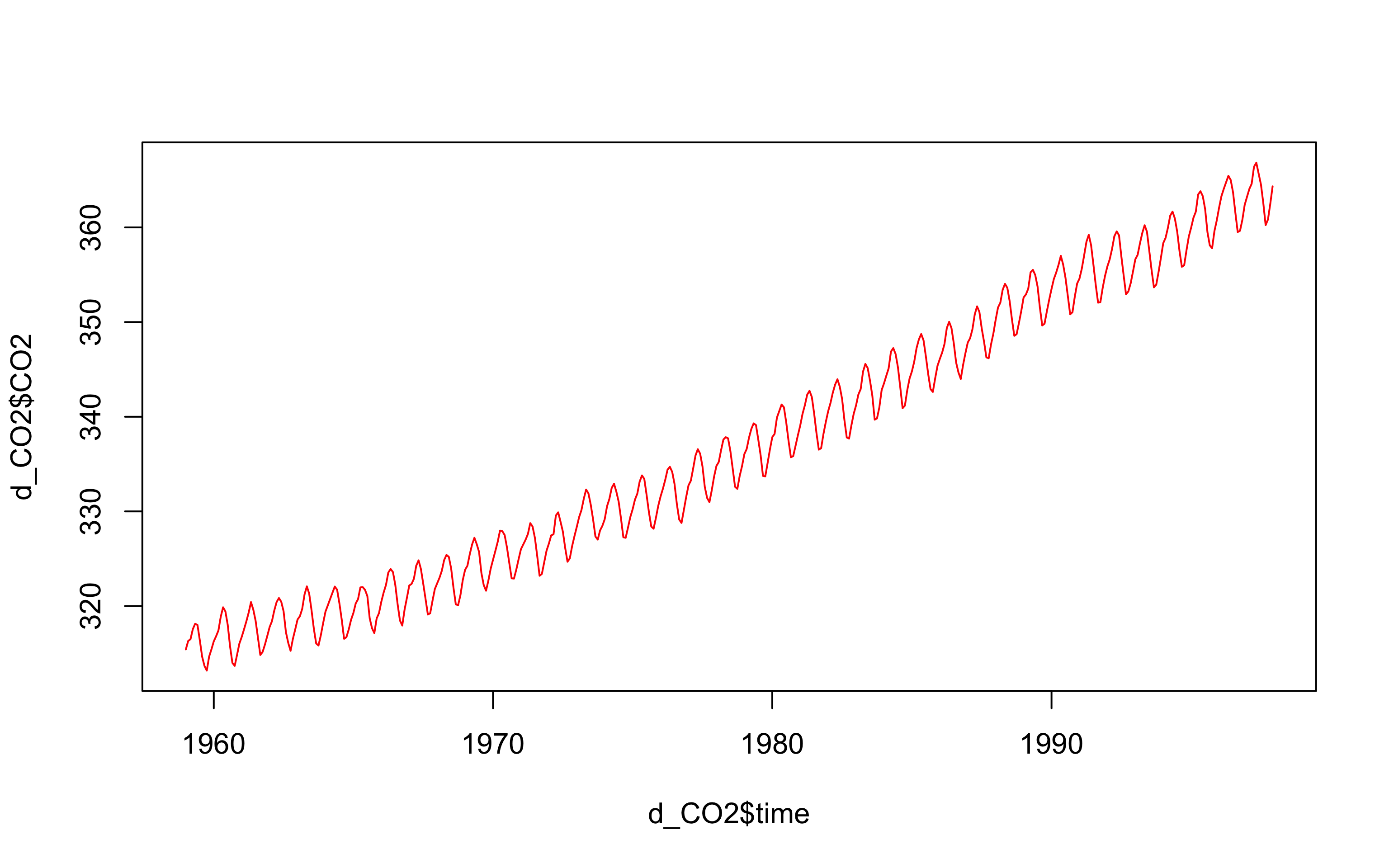
1.14 ggplot作图
先对ggplot绘图有个简单印象,下次课我们深入学习。
library(ggplot2) #ggplot绘图
ggplot(d_CO2, aes(time, CO2))+
theme_bw()+
geom_line(color = "red2")+
labs(x = "Year",
y = ~pCO[2]~(ppm))## Don't know how to automatically pick scale for object of type ts. Defaulting to continuous.
## Don't know how to automatically pick scale for object of type ts. Defaulting to continuous.
#ggsave("pCO2.png", width=342/90, height=243/90, dpi=600)1.16 保存图片
1.16.1 第二种方法
由于我们以后大多使用ggplot()作图,因此可以用ggplot2程序包中的ggsave()函数保存当前显示的图片(在RStudio右下面板中)。
library(ggplot2)
ggplot(mpg, aes(displ, hwy))+
geom_point()
ggsave("myplot_2.png", width=359/90, height=239/90, dpi=600) #png格式,位图
ggsave("myplot_2.pdf", width=359/90, height=239/90) #pdf格式,矢量图完成以上操作,你就能在工作文件夹里找到名称为“myplot_2.png”“myplot_2.pdf”的图了。
如何设置合适的
width和height?
需要一些技巧(我会操作演示)和审美能力。